
Machine Learning BMX Freestyle Trick Classifier
Highlighting the important parts of film is a challenge a variety of sports face, but can save coaches and athletes hours of time each week. With the Australian Cycling BMX Freestyle Team, Eva and the Sports Lab looked to label the tricks each athlete performs during their run. A trick database has the potential to unlock insights into why athletes perform better than others. In order to create this classifier, Eva followed three main steps: markerless motion tracking, Principal Component Analysis (PCA), and machine learning classification.
Eva made a DeepLabCut model to track the bike wheels, handlebars, head of the athlete, and bike crank during a trick [1]. To make the metrics scalable across different parts of the competition course, they calculated the difference between each pairing. These points contain necessary information about the athlete and bike orientation that can be used to differentiate tricks. Figure 1 examines how the Wheel Y and Head/crank metric can be used to differentiate a 360 and a backflip. Since the trick dataset is relatively small, Eva used a method called sampling that injects Gaussian noise into the data to synthesize realistic tricks to bolster the dataset [2].
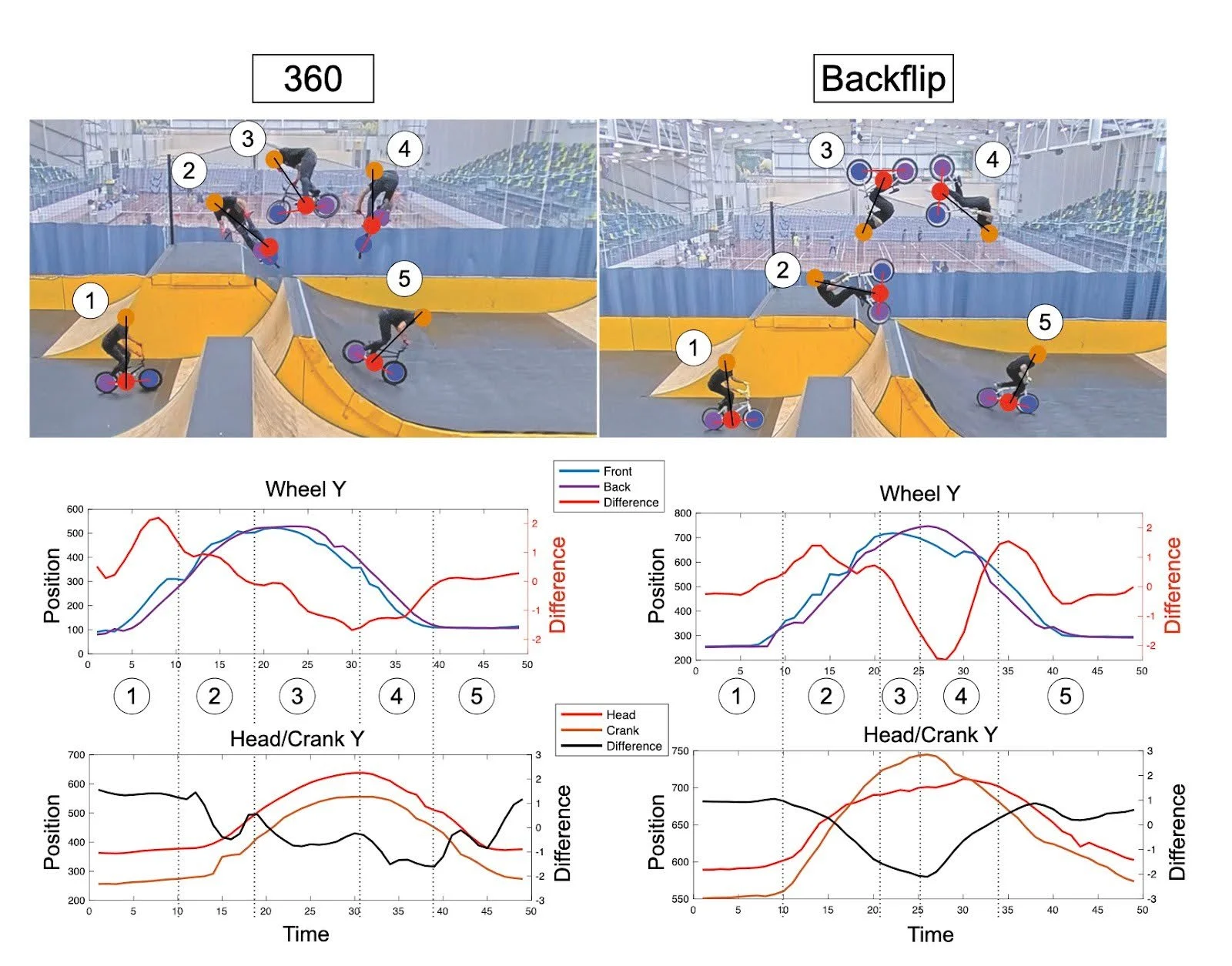
Figure 1: Example of how the tracking metrics, particularly the Wheel and Head/Crank Y difference metrics, can be used to identify tricks. The 360 on the left has a near 0 difference metric in the Y direction, whereas the inversion of the backflip can be seen when the difference is less than 0.
Eva then used singular value decomposition (SVD) to calculate the common basis functions of the tracking data [3]. She used the weights of these basis functions as a unique set of principal components to describe each individual trick. Figure 2 shows the first two principal components of backflips, flairs, and 360s, in the left and right direction. The clustering around trick types shows that these metrics are useful to differentiate between trick types.
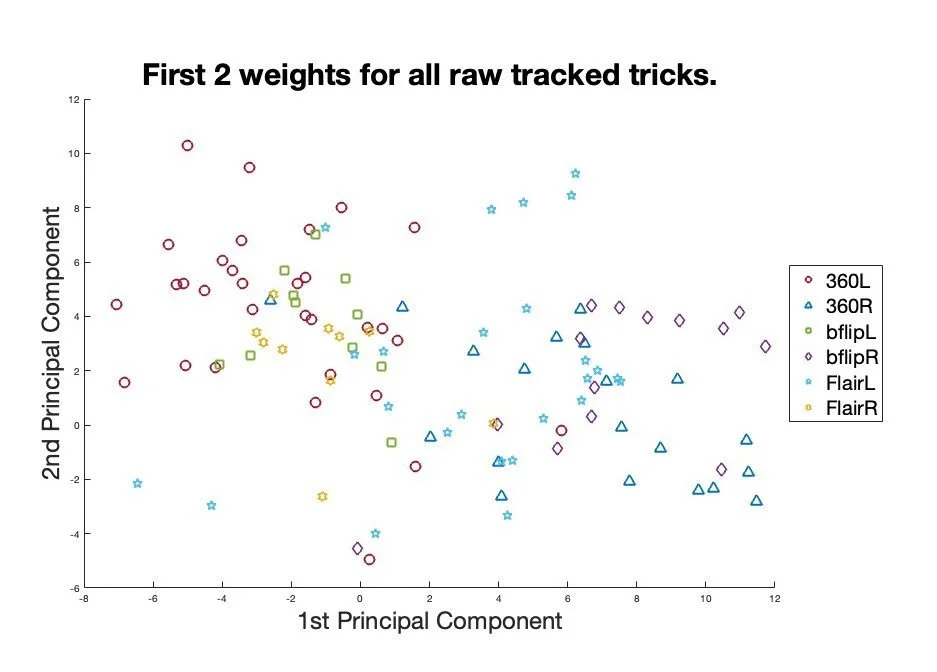
Figure 2: Scatter plot of first two principal components for all tricks in the original dataset: 360, backflip, flair, in the left and right directions. Clustering around each trick type suggests that these metrics can be used to differentiate trick types.
The last step is training a machine learning classifier with these principal components to learn each trick type. Eva applied many models to the dataset, the most successful was Logistic Regression, which resulted in 94.2% Top 1 Accuracy and 99.5% Top 3 Accuracy when trained on 100 principal components. The bolstered dataset contained 411 total tricks. All classifier accuracy results with the sampled dataset are displayed in Figure 3.

Figure 3: BMX Freestyle trick classifier Top 1 and Top 3 Accuracy results. The models used are Support Vector (SVC), Decision Tree (DTC), Random Forest (RFC), Gradient Boosting (GBC), Gaussian Process (GPC), Adaboost (ADA), and Logistic Regression (LOG)
Eva and her team are excited that these results suggest that markerless motion capture combined with PCA is an effective method to reduce sports film to digestible information. She is excited to continue building out her classifier, with the hopes that these techniques become more available to help aesthetic sports take advantage of the data revolution.
About the Author:

Eva Nates completed her mechanical engineering M.S. with the MIT Sports Lab. She received her B.S. in mechanical engineering from Stanford University while competing for the varsity rowing team. A Philly native, she is an avid Philly sports fan. She loves most outdoor activities, ranging from running to cycling to hiking to spikeballing. Eva is particularly excited about AI applications in sports as well as being part of the growing field of women’s sports.
Contact: enates49@mit.edu
References
[1] Mathis, A., Mamidanna, P., Cury, K.M. et al. DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat Neurosci 21, 1281–1289 (2018). https://doi.org/10.1038/s41593-018-0209-y
[2] Q. Wen, L. Sun, F. Yang, X. Song, J. Gao, X. Wang, and H. Xu, “Time series data augmentation for deep learning: A survey,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21 (Z.-H. Zhou, ed.), pp. 4653–4660, International Joint Conferences on Artificial Intelligence Organization, 8 2021. Survey Track.
[3] H. Abdi and L. J. Williams, “Principal component analysis,” WIREs Computational Statistics, vol. 2, no. 4, pp. 433–459, 2010.